Description
Python 练习册,每天一个小程序
Fromshow me the code
Talk is cheap. Show me the code. –Linus Torvalds
第 0000 题: 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果。 类似于图中效果
第 0001 题: 做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)?
-
解答
import mysql.connector import random import string import mysql.connector forSelect = string.ascii_letters + string.digits def gen_code(count, length): for x in range(count): Re = "" for y in range(length): Re += random.choice(forSelect) yield Re def save_code(): conn = mysql.connector.connect(user='root', password='l', database='test') cursor = conn.cursor() codes = gen_code(200, 20) for code in codes: cursor.execute("INSERT INTO `code`(`code`) VALUES(%s)", params=[code]) conn.commit() cursor.close() if __name__ == '__main__': save_code()
第 0002 题: 将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中。
-
解答
import mysql.connector import random import string import mysql.connector forSelect = string.ascii_letters + string.digits def gen_code(count, length): for x in range(count): Re = "" for y in range(length): Re += random.choice(forSelect) yield Re def save_code(): conn = mysql.connector.connect(user='root', password='l', database='test') cursor = conn.cursor() codes = gen_code(200, 20) for code in codes: cursor.execute("INSERT INTO `code`(`code`) VALUES(%s)", params=[code]) conn.commit() cursor.close() if __name__ == '__main__': save_code()
第 0003 题: 将 0001 题生成的 200 个激活码(或者优惠券)保存到 Redis 非关系型数据库中。
-
解答
import redis import random import string forSelect = string.ascii_letters + string.digits def gen_code(count, length): for x in range(count): Re = "" for y in range(length): Re += random.choice(forSelect) yield Re def save_code(): r = redis.Redis(host='127.0.0.1', port='6379', password='linyii') codes = gen_code(200, 20) p = r.pipeline() for code in codes: p.sadd('code', code) p.execute() return r.scard('code') if __name__ == '__main__': save_code()
第 0004 题: 任一个英文的纯文本文件,统计其中的单词出现的个数。
-
解答
from collections import Counter Text = """ bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the Laws of Nature and of Nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation. We hold these truths to be self-evident, that all men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the pursuit of Happiness.--That to secure these rights, Governments are instituted among Men, deriving their just powers from the consent of the governed, --That whenever any Form of Government becomes destructive of these ends, it is the Right of the People to alter or to abolish it, and to institute new Government, laying its foundation on such principles and organizing its powers in such form, as to them shall seem most likely to effect their Safety and Happiness. """ # clean for char in '-.,\n': Text = Text.replace(char, ' ') Text = Text.lower() word_list = Text.split() # solution 1 res = Counter(word_list).most_common() # solution 2 # 使用字典,key-value,单词与个数一一对应 d = {} for word in word_list: # 找到个数然后+1,没有就默认0然后+1 # dict.get(key, default = None) # key − This is the Key to be searched in the dictionary. # default − This is the Value to be returned in case key does not exist. # This method return a value for the given key. If key is not available, then returns default value None. d[word] = d.get(word, 0)+1 # 使用列表为了排序 word_freq = [] for key, value in d.items(): word_freq.append((value, key)) word_freq.sort(reverse=True) # solution 3 # 不使用get()方法 d = {} for word in word_list: if word not in d: d[word] = 0 d[word] += 1 word_freq = [] for key, value in d.items(): word_freq.append((value, key)) word_freq.sort(reverse=True)
第 0005 题: 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。
-
解答
from PIL import Image import os path='/Users/lau/Pictures' resPath='/Users/lau/Desktop' if not os.path.isdir(resPath): os.mkdir(resPath) for fileName in os.listdir(path): # mac系统会出现.DS_Store文件,会报错,所以简单的办法就是 # 去这个文件夹删除隐藏文件 picPath=os.path.join(path,fileName) print(picPath) with Image.open(picPath) as im: im.thumbnail((1366,640)) im.save(resPath+'/f_'+fileName,'jpeg')
第 0006 题: 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
第 0007 题: 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码。包括空行和注释,但是要分别列出来。
第 0008 题: 一个HTML文件,找出里面的正文。
-
解答
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import os def html_body(filesPath): if not os.path.isdir(filesPath): return filesList = os.listdir(filesPath) for file in filesList: filePath = os.path.join(filesPath, file) if os.path.isfile(filePath) and os.path.splitext(filePath)[1] == '.html': with open(filePath) as fileHtml: text = BeautifulSoup(fileHtml, 'lxml') content = text.getText().strip('\n') print(content) if __name__ == "__main__": html_body('./SMTC/source/0008')
第 0009 题: 一个HTML文件,找出里面的链接。
-
解答
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import os def html_link(filesPath): if not os.path.isdir(filesPath): return filesList = os.listdir(filesPath) links = [] for file in filesList: filePath = os.path.join(filesPath, file) if os.path.isfile(filePath) and os.path.splitext(filePath)[1] == '.html': with open(filePath) as fileHtml: text = BeautifulSoup(fileHtml, 'lxml') # 找到a标签 for link in text.find_all('a'): # 获取链接 links.append(link.get('href')) print(links) if __name__ == "__main__": html_link('./SMTC/source/0008')
第 0010 题: 使用 Python 生成类似于下图中的字母验证码图片
-
解答
# -*- coding: utf-8 -*- # 第 0010 题:使用 Python 生成类似于下图中的字母验证码图片 from PIL import Image, ImageDraw, ImageFont, ImageFilter import random def randomLetter(): # 大写字母65-90 # 数字转字符 return chr(random.randint(65, 90)) def randomColor(argc): if argc == 1: return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255)) else: return (random.randint(0, 100), random.randint(0, 100), random.randint(0, 100)) def gen_codepic(savePath): width = 60*4 height = 60 img = Image.new('RGB', (width, height), (255, 255, 255)) # 字体 font = ImageFont.truetype( '/Library/Fonts/Songti.ttc', 36) imgDraw = ImageDraw.Draw(img) for x in range(width): for y in range(height): imgDraw.point((x, y), fill=randomColor(1)) for index in range(4): imgDraw.text((60*index+20, 5), randomLetter(), font=font, fill=randomColor(2)) img = img.filter(ImageFilter.BLUR) img.save(savePath+'codepic.jpg', 'JPEG') if __name__ == "__main__": gen_codepic('./SMTC/source/0010/')
第 0011 题: 敏感词文本文件 filtered_words.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。
北京
程序员
公务员
领导
牛比
牛逼
你娘
你妈
love
sex
jiangge
-
解答
# -*- coding: utf-8 -*- # 敏感词文本文件 filtered_words.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。 import os def Freedom(filesPath): if not os.path.isdir(filesPath): return fileList=os.listdir(filesPath) for file in fileList: filePath=os.path.join(filesPath,file) if os.path.isfile(filePath) and os.path.split(filePath)[1]=='filtered_words.txt': with open(filePath) as text: text=text.read().split('\n') getInput=input('input:') if getInput in text: print('Freedom') else: print('Human Rights') if __name__ == "__main__": Freedom('./SMTC/source/0011')
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。
-
解答
# -*- coding: utf-8 -*- # 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。 import os def Freedom(filePath): word_filter = set() with open(filePath+'filtered_words.txt') as f: for word in f.readlines(): word_filter.add(word.strip()) while True: s = input('input:') if s == 'exit': return for w in word_filter: if w in s: s = s.replace(w, '*'*len(w)) print(s) if __name__ == "__main__": Freedom('./SMTC/source/0011/')
第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-)
-
解答
# -*- coding: utf-8 -*- # 用 Python 写一个爬图片的程序,爬这个链接里的日本妹子图片(http://tieba.baidu.com/p/2166231880) :-) import requests import urllib.request from bs4 import BeautifulSoup import os def spy_pic(url, savePath, header): response = requests.get(url, headers=header) content = BeautifulSoup(response.content, 'lxml') img_tag = content.find_all('img') img_link = [] for i in img_tag: if i.get('pic_type') == '0': img_link.append(i.get('src')) index = 0 if not os.path.exists(savePath): os.mkdir(savePath) for link in img_link: pic_html = requests.get(link) picPath = savePath+str(index+1)+'.'+link.split('.')[-1] with open(picPath, 'wb') as pic: pic.write(pic_html.content) pic.flush pic.close() print('第{0}张图片抓取完成'.format(index+1)) index += 1 print('抓取完成!') if __name__ == "__main__": reqHeader = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7', 'Cookie': 'TIEBA_USERTYPE=7b00a4223cb9934b1b9270ad; wise_device=0; bdshare_firstime=1549795215089; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1549795215; Hm_lvt_287705c8d9e2073d13275b18dbd746dc=1549795216; Hm_lpvt_98b9d8c2fd6608d564bf2ac2ae642948=1549847500; Hm_lpvt_287705c8d9e2073d13275b18dbd746dc=1549847500; BAIDUID=48130036CAF55267908C2180103698DC:FG=1; cflag=13%3A3; BDUSS=HN6WUx-aGVQMGlNR0NlcEhCd0pjUkJVQXpBbWFxY3hYTjZNfmozdjV6RFlkb2hjQVFBQUFBJCQAAAAAAAAAAAEAAAAZhpwmbmljZWxpdXppAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANjpYFzY6WBcO; TIEBAUID=35f770fc8e0ac33633210842; STOKEN=42c9d0d4dc2e420802cf269968ec38e4101a2a5d7f095a603f36b0261f413597', 'Host': 'tieba.baidu.com', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36' } spy_pic('http://tieba.baidu.com/p/2166231880', './SMTC/source/0013/', reqHeader ) -
效果展示

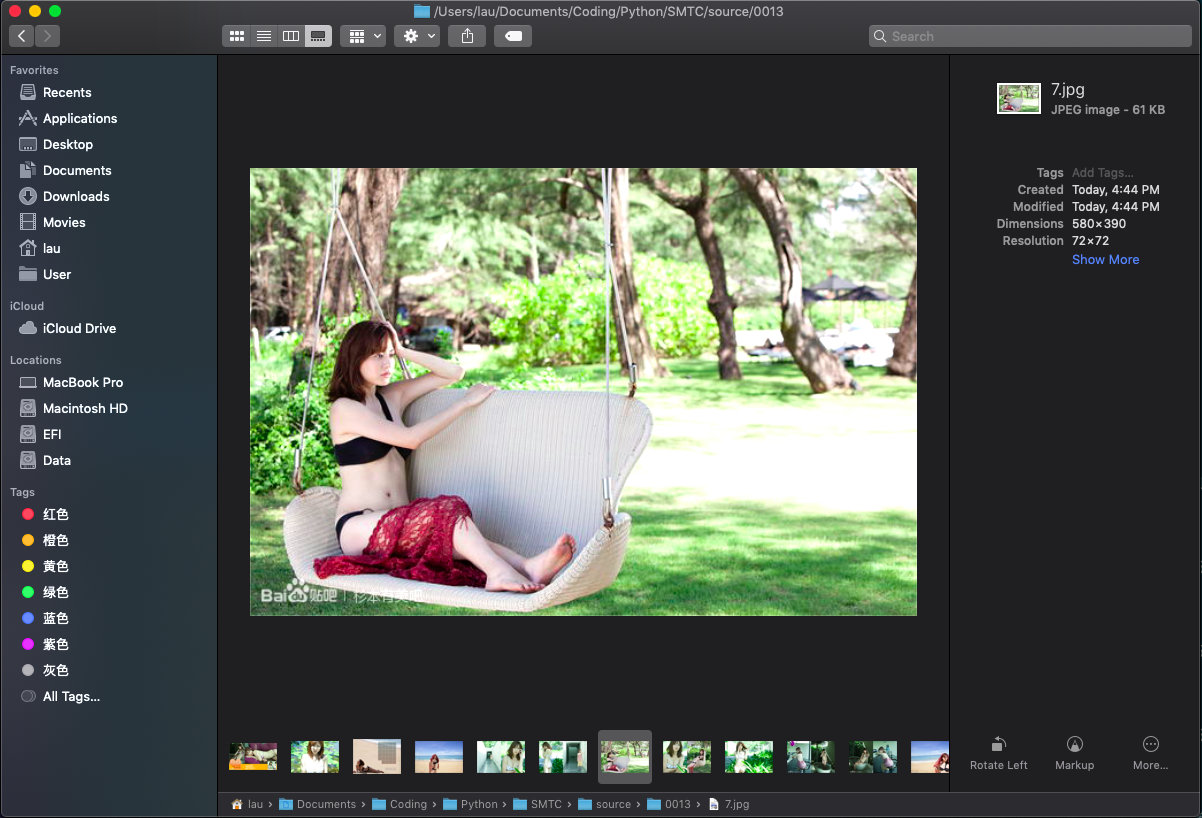
-
参考
第 0014 题: 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示:
{
"1":["张三",150,120,100],
"2":["李四",90,99,95],
"3":["王五",60,66,68]
}
请将上述内容写到 student.xls 文件中,如下图所示:
-
阅读资料 腾讯游戏开发 XML 和 Excel 内容相互转换
-
解答
# -*- coding: utf-8 -*- # 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示 from xlwt import Workbook import json def xml2exl(filePath): with open(filePath+'student.txt', 'r') as dic: content = json.load(dic) workbook = Workbook() sheet = workbook.add_sheet('student', cell_overwrite_ok=True) # 输出元素序号 for index, (key, values) in enumerate(content.items()): # sheet.write(row, col, *args) # 输入第一列数据 sheet.write(index, 0, key) for i, value in enumerate(values): # 输入每一行第二列开始的数据 sheet.write(index, i+1, value) workbook.save(filePath+'student.xls') if __name__ == "__main__": xml2exl('./SMTC/source/0014/')
第 0015 题:
{
"1" : "上海",
"2" : "北京",
"3" : "成都"
}
请将上述内容写到 city.xls 文件中,如下图所示:
-
解答
# -*- coding: utf-8 -*- # 纯文本文件 city.txt为城市信息, 里面的内容(包括花括号)如下所示: from xlwt import Workbook import json def xml2exl(filePath): with open(filePath+'city.txt', 'r') as f: content = json.load(f) workBook = Workbook() sheet = workBook.add_sheet('city', cell_overwrite_ok=True) # enumerate可以分开词语 for index, (key, value) in enumerate(content.items()): sheet.write(index, 0, key) # 与上一题不同的是 # 这题中的value只有一列值 # 不需要使用enumerate sheet.write(index, 1, value) workBook.save(filePath+'city.xls') if __name__ == "__main__": xml2exl('./SMTC/source/0015/')
第 0016 题: 纯文本文件 numbers.txt, 里面的内容(包括方括号)如下所示:
[
[1, 82, 65535],
[20, 90, 13],
[26, 809, 1024]
]
请将上述内容写到 numbers.xls 文件中,如下图所示:
-
解答
# -*- coding: utf-8 -*- # 纯文本文件 numbers.txt, 里面的内容(包括方括号) from xlwt import Workbook import json def json2xls(filePath): with open(filePath+'numbers.txt', 'r') as f: content = json.load(f) workbook = Workbook() sheet = workbook.add_sheet('numbers', cell_overwrite_ok=True) for row, list in enumerate(content): for col, value in enumerate(list): sheet.write(row, col, value) workbook.save(filePath+'numbers.xls') if __name__ == "__main__": json2xls('./SMTC/source/0016/')
第 0017 题: 将 第 0014 题中的 student.xls 文件中的内容写到 student.xml 文件中,如
下所示:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<students>
<!--
学生信息表
"id" : [名字, 数学, 语文, 英文]
-->
{
"1" : ["张三", 150, 120, 100],
"2" : ["李四", 90, 99, 95],
"3" : ["王五", 60, 66, 68]
}
</students>
</root>
-
解答
# -*- coding: utf-8 -*- # 将 第 0014 题中的 student.xls 文件中的内容写到 student.xml 文件中 from xml.dom.minidom import Document import xlrd def xls2xml(filePath): doc = Document() root = doc.createElement('root') doc.appendChild(root) students = doc.createElement('students') root.appendChild(students) comment = doc.createComment('学生信息表\n\t\t"id" : [名字, 数学, 语文, 英文]\n\t\t') students.appendChild(comment) content = xlrd.open_workbook(filePath+'student.xls') sheet = content.sheet_by_index(0) nrows = sheet.nrows sheet_content = dict() for i in range(nrows): sheet_content[str(sheet.cell(i, 0).value)] = sheet.row_values(i)[1:] students.appendChild(doc.createTextNode(str(sheet_content))) with open(filePath+'student.xml', 'w') as student_xml: student_xml.write(doc.toprettyxml()) if __name__ == "__main__": xls2xml('./SMTC/source/0014/')
第 0018 题: 将 第 0015 题中的 city.xls 文件中的内容写到 city.xml 文件中,如下 所示:
<?xmlversion="1.0" encoding="UTF-8"?>
<root>
<cities>
<!--
城市信息
-->
{
"1" : "上海",
"2" : "北京",
"3" : "成都"
}
</cities>
</root>
-
解答
# -*- coding: utf-8 -*- # 将 第 0015 题中的 city.xls 文件中的内容写到 city.xml 文件中 from xml.dom.minidom import Document import xlrd def xls2xml(filePath): doc = Document() root = doc.createElement('root') doc.appendChild(root) cities = doc.createElement('cities') root.appendChild(cities) comment = doc.createComment('\n\t\t城市信息\n\t\t') cities.appendChild(comment) content = xlrd.open_workbook(filePath+'city.xls', 'r') sheet = content.sheet_by_index(0) nrows = sheet.nrows sheet_content = dict() for i in range(nrows): sheet_content[sheet.cell(i, 0).value] = sheet.row_values(i)[1:] cities.appendChild(doc.createTextNode(str(sheet_content))) with open(filePath+'city.xml', 'w') as f: f.write(doc.toprettyxml()) if __name__ == "__main__": xls2xml('./SMTC/source/0015/')
第 0019 题: 将 第 0016 题中的 numbers.xls 文件中的内容写到 numbers.xml 文件中,如下
所示:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<numbers>
<!--
数字信息
-->
[
[1, 82, 65535],
[20, 90, 13],
[26, 809, 1024]
]
</numbers>
</root>
-
解答
# -*- coding: utf-8 -*- # 将 第 0016 题中的 numbers.xls 文件中的内容写到 numbers.xml 文件中 from xml.dom.minidom import Document import xlrd def xls2xml(filePath): doc = Document() root = doc.createElement('root') doc.appendChild(root) numbers = doc.createElement('numbers') root.appendChild(numbers) numbers.appendChild(doc.createComment('\n\t\t数字信息\n\t\t')) content = xlrd.open_workbook(filePath+'numbers.xls') sheet = content.sheet_by_index(0) nrows = sheet.nrows sheet_list = list() for i in range(nrows): sheet_list.append(sheet.row_values(i)) numbers.appendChild(doc.createTextNode(str(sheet_list))) with open(filePath+'numbers.xml', 'w') as f: f.write(doc.toprettyxml()) if __name__ == "__main__": xls2xml('./SMTC/source/0016/')
第 0020 题: 登陆中国联通网上营业厅 后选择「自助服务」 –> 「详单查询」,然后选择你要查询的时间段,点击「查询」按钮,查询结果页面的最下方,点击「导出」,就会生成类似于 2014年10月01日~2014年10月31日通话详单.xls 文件。写代码,对每月通话时间做个统计。
-
解答
# -*- coding: utf-8 -*- import time import re import xlrd def str2sec(str): sec = 0 time_re = re.compile(r'(\d+)(\D+)') time_list = time_re.findall(str) for time_item in time_list: if time_item[1] == '秒': sec += int(time_item[0]) elif time_item[1] == '分': sec += int(time_item[0]) * 60 elif time_item[1] == '小时': sec += int(time_item[0]) * 3600 return sec def sec2str(sec): h = sec // 3600 m = sec % 3600 // 60 s = sec % 60 return '%s小时%s分%s秒' % (h, m, s) def minidata(): all_time = 0 # 使用总时间(秒) start_time = time.mktime(time.strptime('2018-09-01', '%Y-%m-%d')) end_time = time.mktime(time.strptime('2018-10-01', '%Y-%m-%d')) data = xlrd.open_workbook('./SMTC/source/0020/2018年09月语音通信.xls') table = data.sheet_by_index(0) nrows = table.nrows for i in range(nrows): if i == 0: continue this_time = time.mktime(time.strptime( table.row_values(i)[2], '%Y-%m-%d %H:%M:%S')) if this_time >= start_time and this_time < end_time: all_time += str2sec(table.row_values(i)[3]) print('总时间:'+sec2str(all_time)) if __name__ == "__main__": minidata()
第 0021 题: 通常,登陆某个网站或者 APP,需要使用用户名和密码。密码是如何加密后存储起来的呢?请使用 Python 对密码加密。
-
阅读资料 用户密码的存储与 Python 示例
-
阅读资料 Python’s safest method to store and retrieve passwords from a database
-
解答
# -*- coding: utf-8 -*- import os from hashlib import sha256 from hmac import HMAC def encrypt_passwd(password, salt=None): if salt is None: salt = os.urandom(8) assert 8 == len(salt) assert isinstance(salt, bytes) assert isinstance(password, str) if isinstance(password, str): password = password.encode('utf-8') assert isinstance(password, bytes) for i in range(10): password = HMAC(password, salt, sha256).digest() # print('password:', password) return salt+password def validate_passwd(hashed, input): return hashed == encrypt_passwd(input, hashed[:8]) if __name__ == "__main__": hashed = encrypt_passwd('123456') print(validate_passwd(hashed, '123456'))
第 0022 题: iPhone 6、iPhone 6 Plus 早已上市开卖。请查看你写得 第 0005 题的代码是否可以复用。
第 0023 题: 使用 Python 的 Web 框架,做一个 Web 版本 留言簿 应用。
第 0024 题: 使用 Python 的 Web 框架,做一个 Web 版本 TodoList 应用。
第 0025 题: 使用 Python 实现:对着电脑吼一声,自动打开浏览器中的默认网站。
例如,对着笔记本电脑吼一声“百度”,浏览器自动打开百度首页。
关键字:Speech to Text
参考思路: 1:获取电脑录音–>WAV文件 python record wav
2:录音文件–>文本
STT: Speech to Text
STT API Google API
3:文本–>电脑命令