-
来源:http://aclweb.org/anthology/D14-1181
-
机构:NYU
-
一个简单的CNN模型使用两个chanel就可以在不同的数据集上去的不错的成绩
-
论文非常清晰的表达出了自己的主要工作内容,从预训练词向量是重要的universal的特征抽取器,CNN常用于CV,而在NLP上也很有用,讲述为什么用CNN+word2vec,到本文使用的简单模型结构以及数学原理,还有重要的模型设置——dropout,再到实验的设置,超参,预训练,模型的变体,实验结果,最后到结果分析,分别讨论模型的重要创新点,multichanel,static表示,以及其他的实验发现。
-
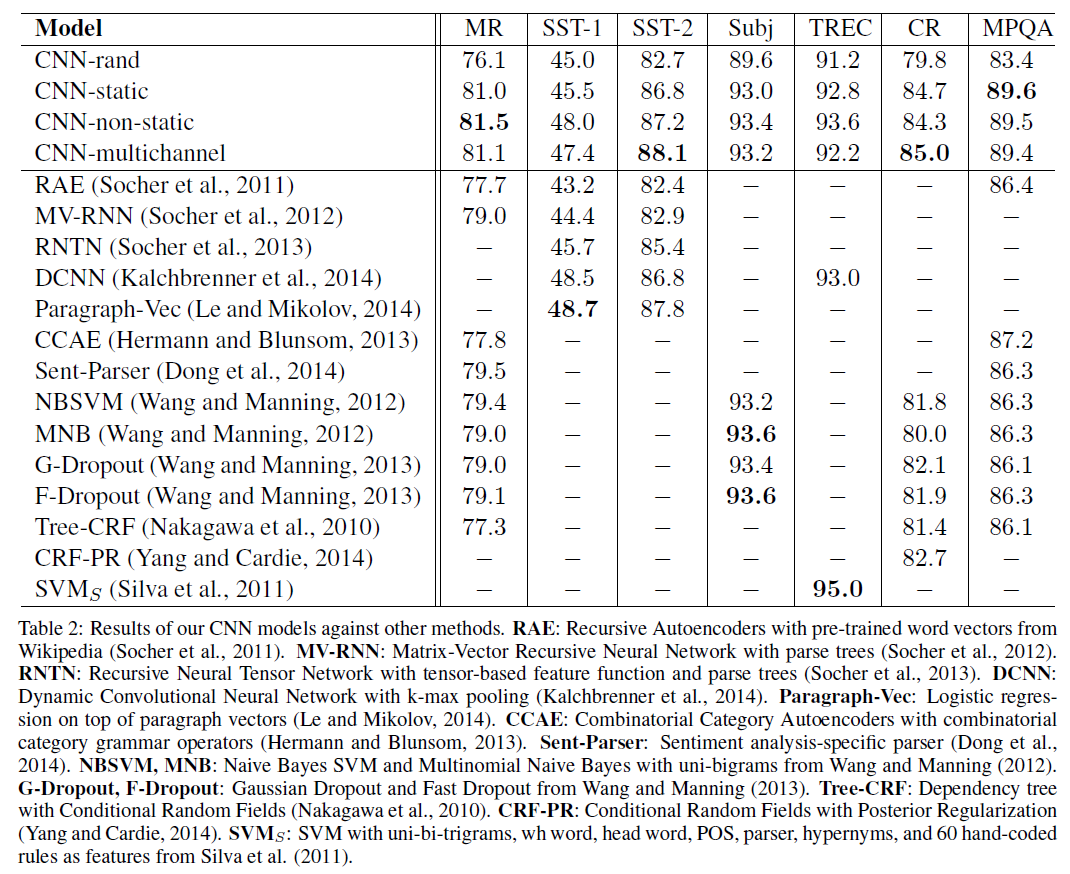
提出了一个简单的CNN模型来做句子分类,仅仅只是word2vec+CNN+最大池化+全连接层就可以达到不错的性能
-
使用了预训练模型Word2vec,实验证明了预训练模型模型对于缺乏大规模训练数据集的任务很有帮助,做了一个很好的初始化,多个卷积核和feature map显示了模型强大的容量
-
dropout有助于大模型的正则化
-
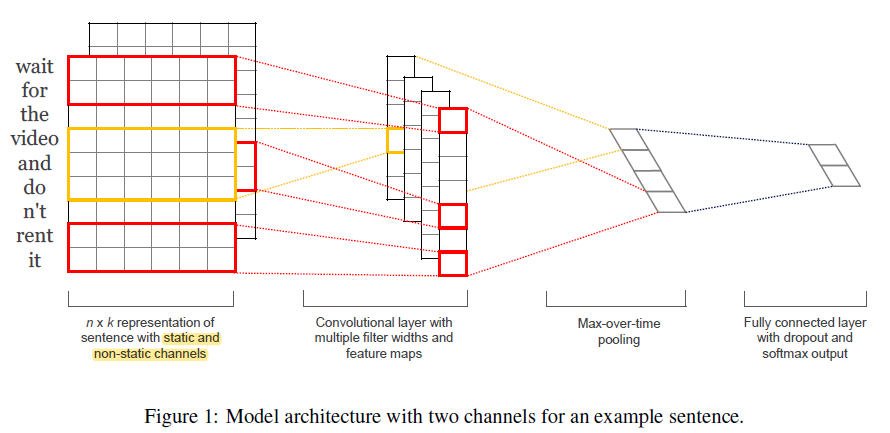
两个Chanel,防止微调层的向量偏差原始的太远,一定程度上防止了过拟合
-
-
-