背景
-
什么类型的信息在影响着RE模型区分句子包含什么关系?
- 句子中两个重要的信息:上下文和实体mention
- 对于人类直觉来说,句子的上下文对我们影响更大
- 之后的方法倾向于编码成分布式表示并进行匹配从而实现预测关系分类
- 影响程度:
- 两种信息都很重要
- 现有的RE数据集在训练过程中会从实体提及中泄露一部分信息,提高了性能
- 以后的方向:更好地理解句子的上下文以及利用实体提及。防止只是简单的记忆(拟合)
- 本文使用wikidata去聚类相同的关系实例,学习去分辨句子之间的相似度和属于不同的关系
-
模型
- CNN
- BERT
- BERT for RE following Baldini Soares et al. (2019)
- MTB
- Baldini Soares et al. (2019)
- pre-train a BERTbase version of MTB

- CP
-
实验
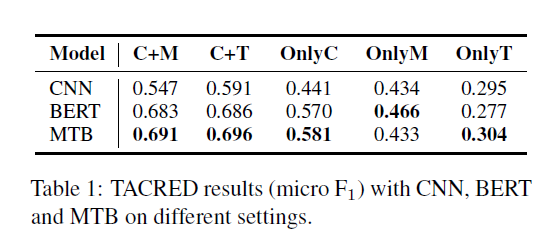
- Context+Mention (C+M)
- Context+Type (C+T)
- We replace entity mentions with their types provided in TACRED.
- We use special tokens to represent them:
- for example, we use [person] and [date] to represent an entity with type person and date respectively.
- we do not repeat the special tokens for entity-length times to avoid leaking entity length information
- Only Context (OnlyC)
- we replace all entity mentions with the special tokens [SUBJ] and [OBJ]. In this case, the information source of entity mentions is totally blocked
- Only Mention (OnlyM)
- Only Type (OnlyT)
-
分析
- 目前的模型对句子的语义信息的理解还不够,仅仅保持在记忆的阶段
- 模型从实体名称中所利用的大部分信息是type信息
- 基于实体名称的模型在预测阶段可能会受到训练集的bias,另一方面,单纯的C+T可能无法更好的理解文本
- 错误分析-onlyC

- wrong:可以推测出来但是模型预测错误:almost half
- no pattern:人类也无法根据上下文推测出句子包含的关系
- confusing:句子的意思模糊
Contrastive Pre-training for RE
- 生成数据
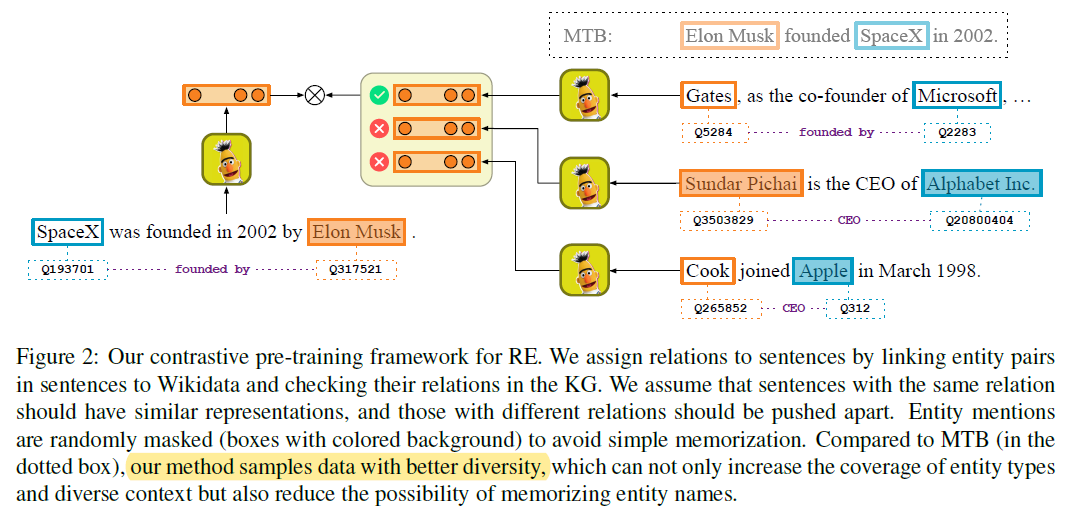
- 数据需要包含足够的区别,不能仅仅增加实体类型和不同的上下文,也要避免模型记住实体的mention
- contrastive learning:Hadsell et al., 2006
- 随机mask实体,70%,
- 模型的主要目标是,使学习到的具有相同关系的句子的representation相似,而不同关系的句子的representation区分开来
- 所以存在噪音也是可以接受的
- 训练
- 损失函数
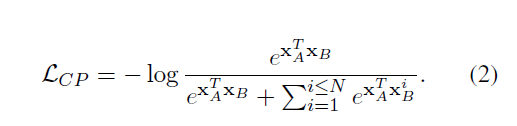
- 其中
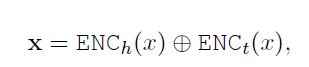
- h和t是[E1],[E2] $ENC_i()$是transformer的encoder输出
- Denote the MLM loss as LMLM
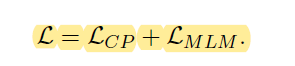
- 损失函数
实验
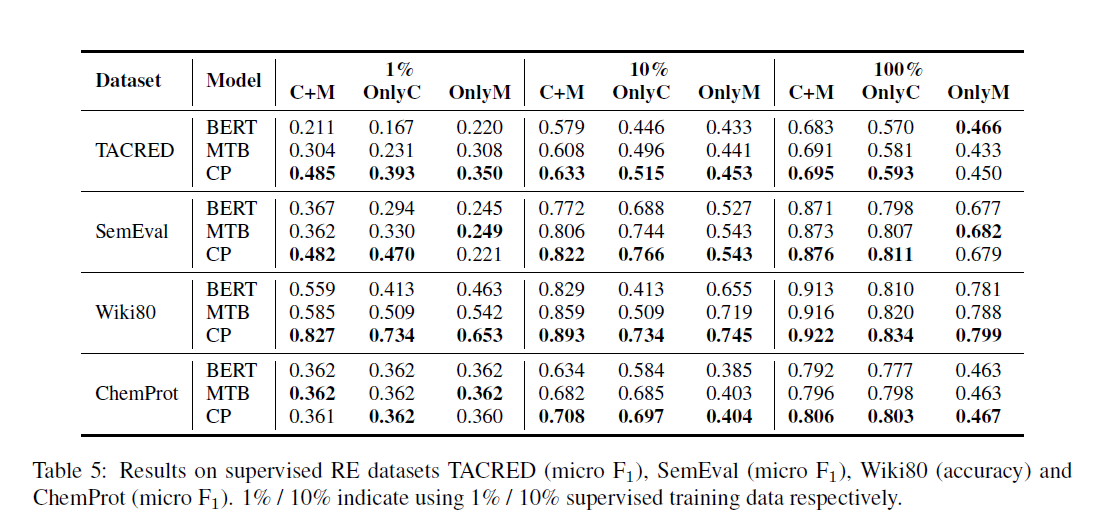
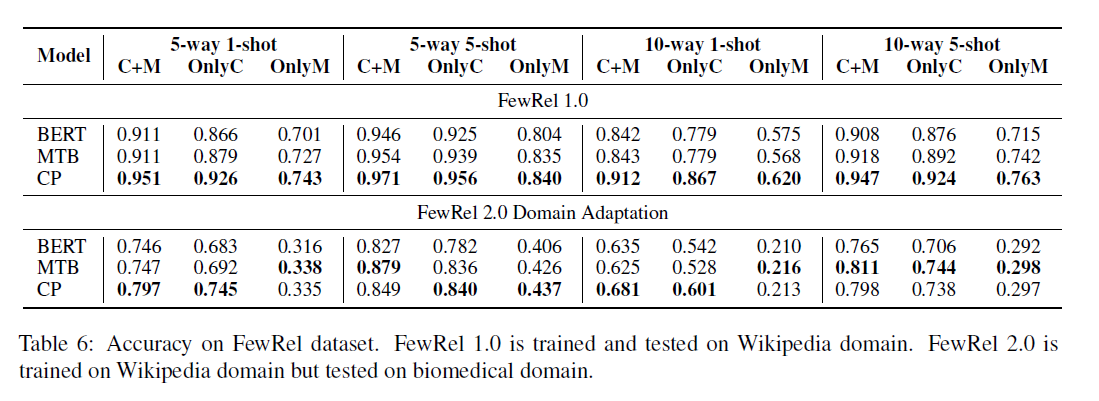
- 在[[Han et al_2018_FewRel]]的基础上对模型进行修改
- 使用[E1],[E2]作为表示,而不是[CLS]
- 使用点积,而不是欧几里得距离计算相似度
- 性能提高“a large margin”
- 性能
- 在all C+M,OnlyC and OnlyM都取得了提升