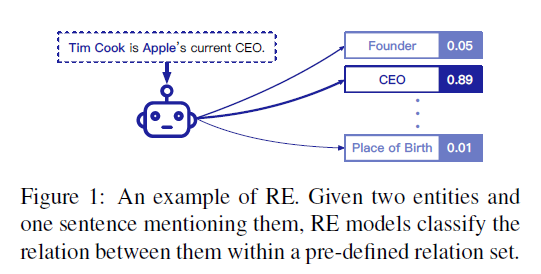
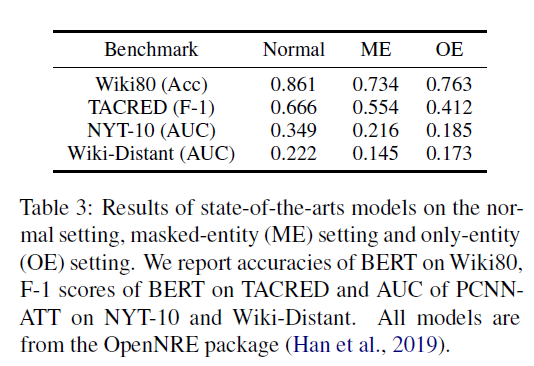
These methods mainly focus on training models with large amounts of human annotations to classify two given entities within one sentence into pre-defined relations.
现实情况下会更加复杂:
高质量人工标注数据代价高
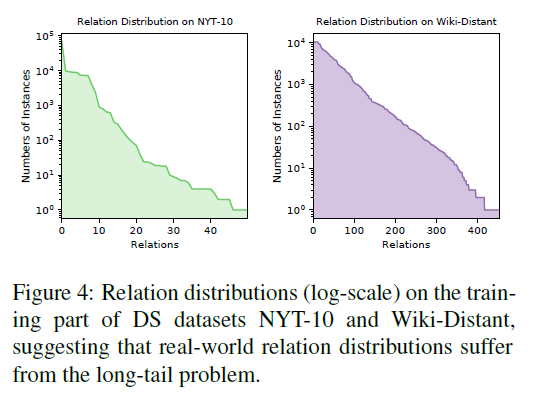
关系抽取数据存在长尾现象
大部分的事实数据是出现在更大的上下文中,多个句子中
预先定义好的关系集合无法覆盖所有实际存在的关系
概括出四个可行的方向
利用更多的数据
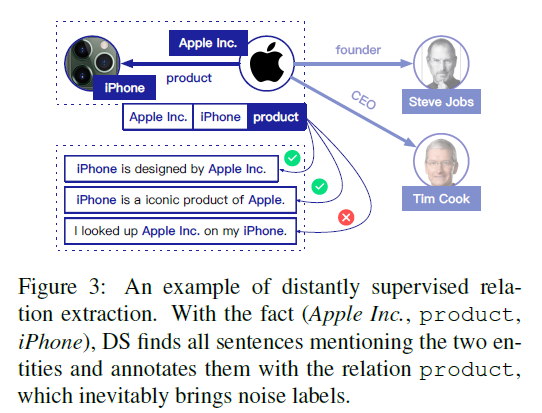
[[Distant Supervision|远程监督]]
但是,DS带来标签错误问题,单个句子包含实体对
如何利用远程监督或者其他方法来获取高质量、大规模的数据去训练?
更有效率的学习
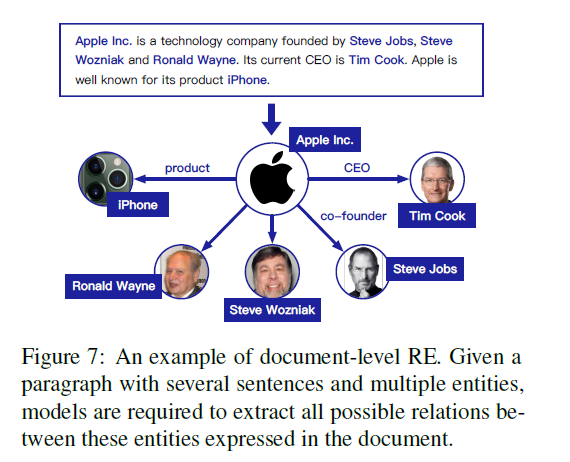
更加复杂的上下文
现在的大部分模型都是抽取单句内的关系,两句或更大的上下文还无法很好的利用
开放域
关键挑战
[[Peng et al_2020_Learning from Context or Names|learning from text or names]]