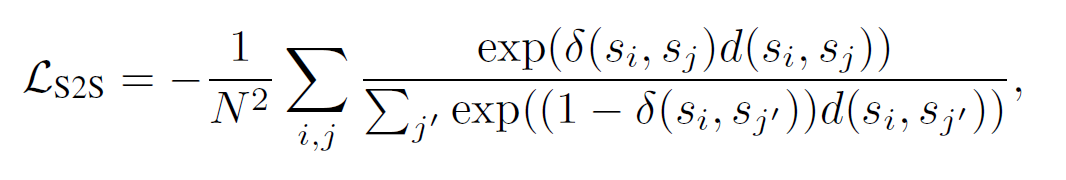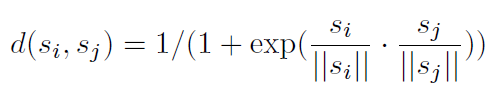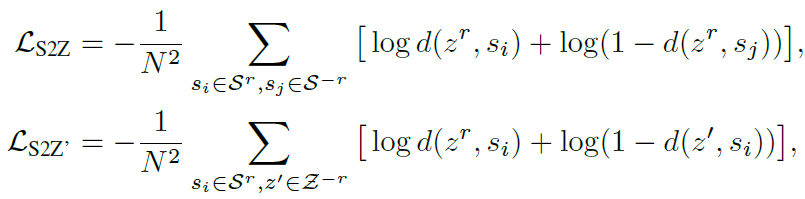针对有监督数据集,大部分模型都能够处理的很好,但是数据量小,人工标注成本高。所以使用远程监督(启发式规则)的方法自动构造数据,不可避免会带有大量噪音标签
但是遇到远程监督数据集效果一般不好
远程监督数据集含有大量的标签噪音
语言的表达多种多样
解决办法#
预训练-微调范式
先在大规模远程监督数据集上预训练,然后针对不同的任务在目标数据集上微调
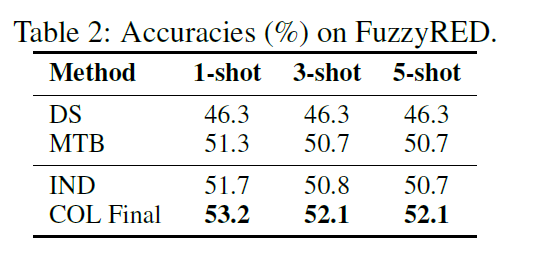
FuzzyRED dataset
学习句子statement的representation
指示函数包含相同关系返回1,否则0
相似度计算,对长度归一化
为什么不用点乘,作者回复说是选择这个loss是为了模型在几何上的可解释性
而点积会导致公式计算时出现问题
这里是沿用了[[Baldini SoaresL(2019)_Matching the Blanks]]中的loss
但是并没有做消融实验验证这个相似度计算方法是否比点乘优秀
存在一个问题,当$s_i$和$s_j$距离近时,这个相似度应该是高的,但是这个式子得出的值实际上会很小,所表达的应该是不相似度,这个问题在rebuttal的时候也被提出来了
分子让具有相同关系的statement距离更近,分子让其他不同关系分离开
1Vn,negative pairs具有更大的权重
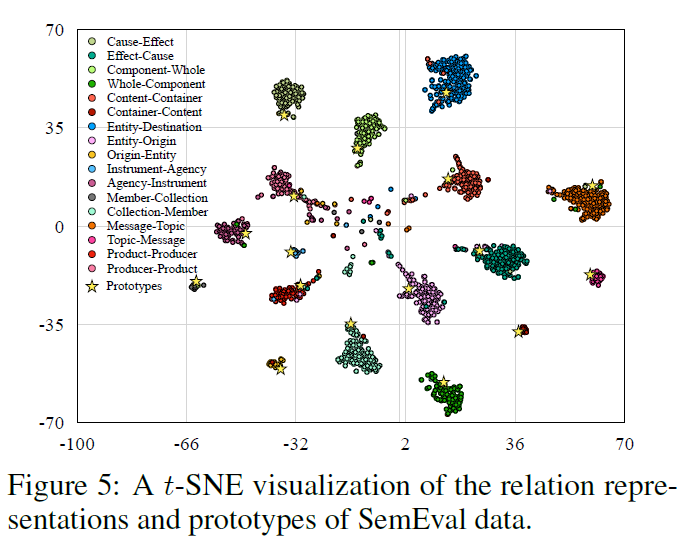
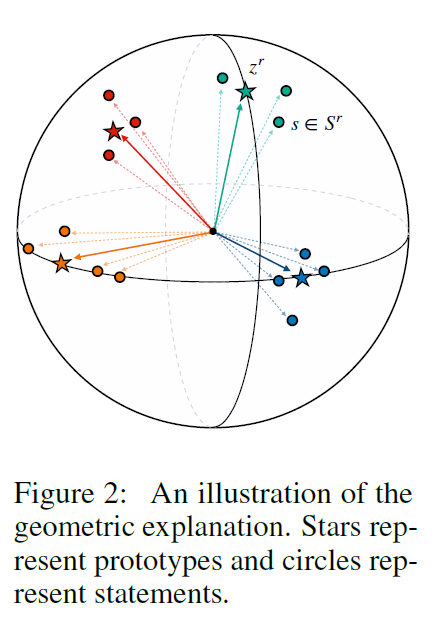
statements和proto
第一个式子表示,对于一个关系的 proto 来说,同类的 instance 要近,不同类的要远;第二个式子表示,对于一个 instance 来说,要跟自己的 proto 近,跟别的 proto 远
关系r的prototype和包含r的statements距离要比其他关系的statements要小
包含r的statements和关系r的prototype距离要比其他关系的prototype要小
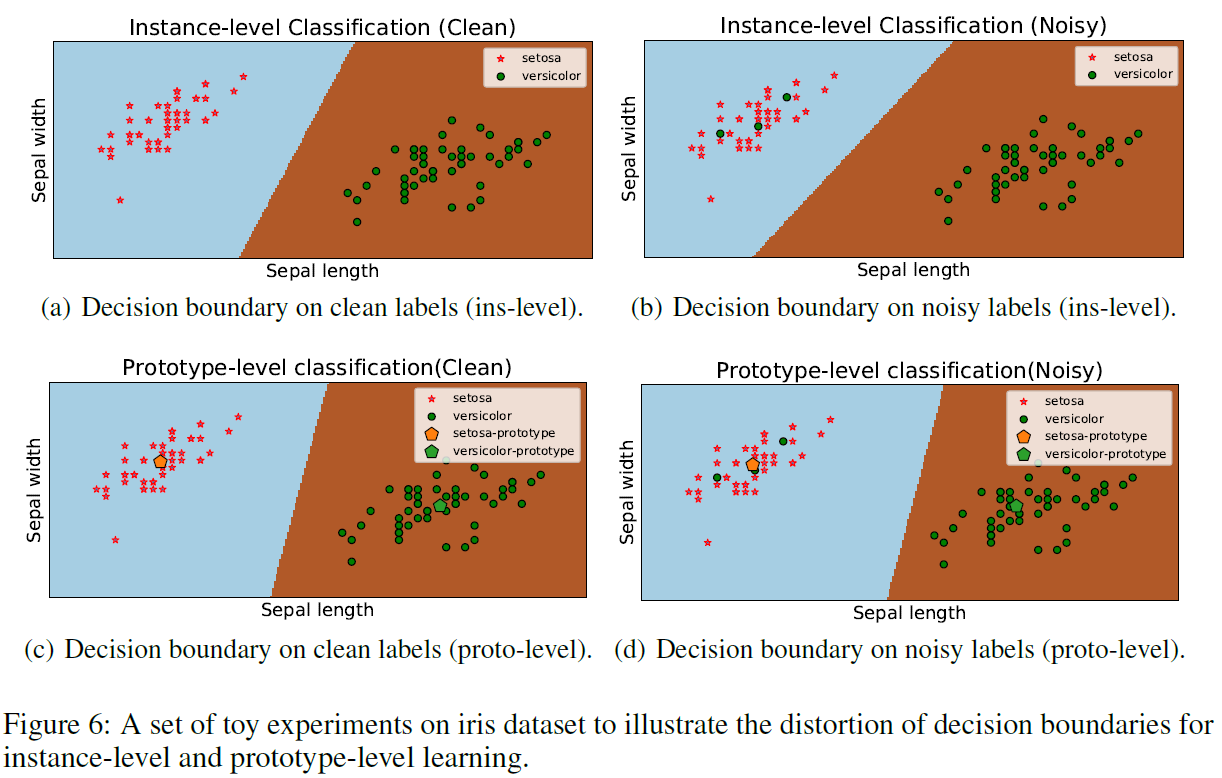
交叉熵proto是直接求质心,本文是计算与各个样本、其它 proto 相互位置关系,这样抗噪性能显著增强,分类边界受噪声样本的干扰明显变小
实验设置
数据
aligning relation tuples from the Wikidata database to Wikipedia articles
more than 0.86 million relation statements covering over 700 relations
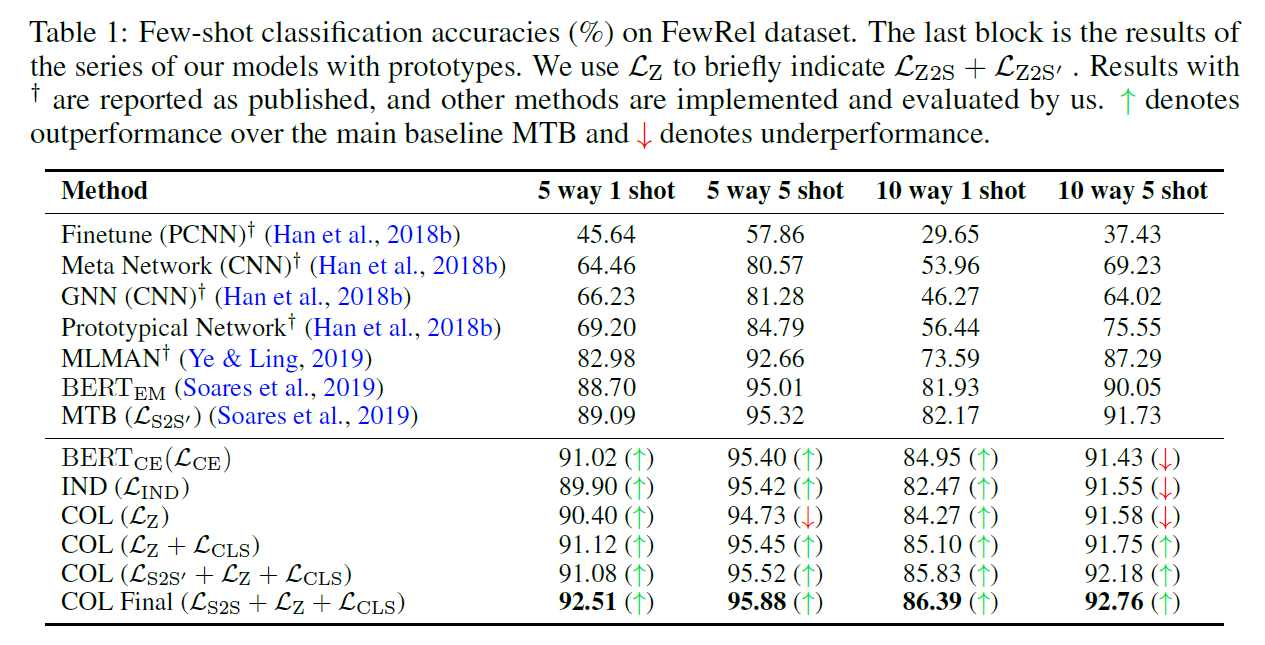
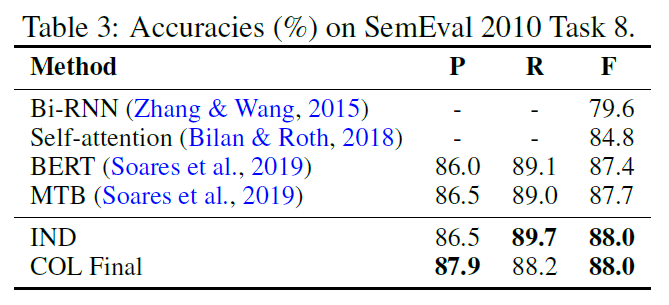
baseline
PCNN, Meta Network, GNN, Prototypical Network, MLMAN等使用开源代码
MTB:在本文整理的数据集上训练出的性能比论文的低
IND:topK取平均
有监督
few-shot
700*100,64+16+20
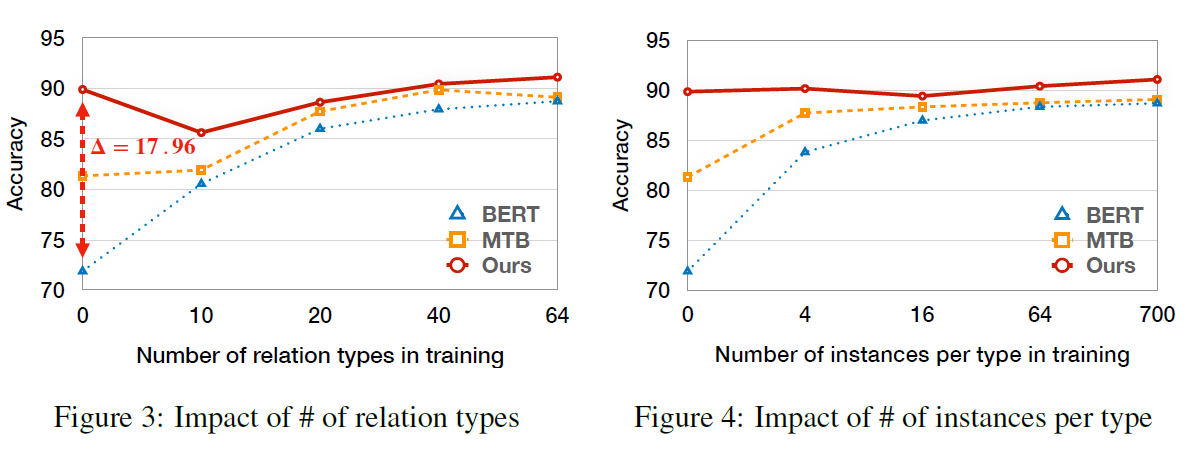
不用训练数据的时候,相比baseline居然有17.6的F1提升,有些反直觉
关系种类的多样性对于性能的提升更大
fuzzy
1000个句子,20种关系
里面有一半是远程监督的噪声,即包含两个实体但是不表达那个关系
性能
在supervised,few-shot, and zero-shot任务中超越SOTA
鲁棒性
可解释性
相似工作
Row-less universal schema,2016
Prototypical networks for few-shot learning,2017
Review
“Overall, I think the proposed approach is quite reasonable and also seems to work well in the evaluation tasks (learning prototype embeddings instead of taking the average of instance embeddings and adopting contrastive losses between relation statements and prototypes). However, I think the paper has many clarity and presentation issues that make it difficult to evaluate the significance of the work.”
Please enable JavaScript to view the comments powered by Disqus.