问题
协变量偏移,该问题是由受外部知识图约束的带噪声标签的训练集与人工注释的测试集之间的不一致引起的。 作者提出了一种联合提取方法,通过使用一组协作式多智能体(cooperative multiagents)重新标记噪音实例来解决此问题。
- 人工标注价格昂贵,所以出现了[[Distant Supervision]]方法,通过将外部的知识图谱对齐到语料库自动生成训练数据,但是会引入噪音标注,降低模型性能。
- 前人解决办法
- 概率图模型
- 注意力机制神经网络
- 强化学习选择
- 但是,大部分现存的工作都忽视了标签分布偏移问题
- 两种标注噪音
- False Positive:没有关系的实体对被标记了关系
- False Negative:有关系的实体对被忽视或者标记了None
- 这里的是False Negative还是True Negative?
- 这里的False代表的是这条数据存在噪音,怎么判断噪音呢?DS生成的关系与base抽取器抽取出的关系不同,就认定为存在噪音(争议)。
- Neg代表的是DS数据集中关系为None,但是抽取出有关系,Pos则相反。
- 现存的降噪工作基本都是通过对噪音数据分配低权重或者直接舍弃,并没有解决这个问题,将其恢复到正确的标注
- 并且pipeline模式会产生错误级联,加剧标签分布问题
本文方法
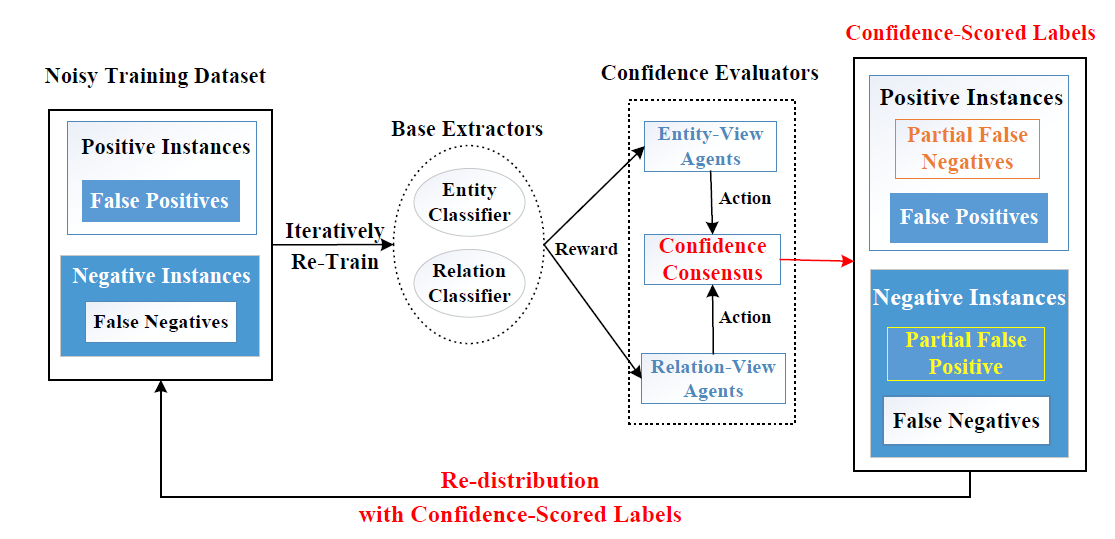
- 每一个agent会通过计算连续的confidence score来evaluate实例
- confidence score可以用来将噪音训练数据重新分布、调整更新训练loss
- confidence consensus用来汇合所有agent计算到的一个特征,其实也就是平均
- 两个任务(实体抽取和关系抽取)之间存在某种联系和相互增强的作用,可以为减少噪音提供一些提示和帮助 -> 联合模型
- 主要流程
- 输入:远程监督训练数据$D={s_1,…,s_n}$,实体抽取器${\theta}_e^{'}$,关系抽取器${\theta}_r^{'}$(都是在D上用预训练模型进行[[Fine Tune|微调]]的)
- multiagents利用confidence-scored label对训练集D进行重新分布,然后利用修改后的标签重新对${\theta}_e^{'}$和${\theta}_r^{'}$进行训练得到最终的抽取器。
- 本文为了达到上述的目标,将问题建模成一个mltuiagents强化学习的问题
- 因为我们没有测试集的gold label的数据,没法判断调整之后的label的正确性,所以使用RL来利用validation set上的性能标准来间接判断好坏
- 两个抽取器之间通过intermediate agent来交换信息
- 利用在validation上的性能分数和一致的分数来对agents进行reward
- 这个方法可以看作是后处理
- Confidence Evaluators as Agents
- status
- entity:现在的句子、抽取结果(类型)、噪音标签类型
- relation:句子、抽取类型、噪音标签
- 复用了base抽取器的句子和type向量,使其轻量化
- Actions
- 利用神经网络去决定当前的句子是pos or neg,并且计算confidence score
- pos:根据抽取出来的关系类型
- neg:None type
- 使用[Gated Recurrent Unit]来作为[[Policy Network]],通过一个[[Sigmoid Function]]来计算概率,其实也就是confidence score,1/0分别对应pos/neg
- 通过使用多个agents来解决state spaces太大的问题,如何解决的:
- 目标类型使用agents数量平均分
- 每个agents只负责一部分
- 前面提到过不同agents之间交互是通过一个叫做intermediate agents实现的
- 每个句子对应一个r agent和2个e agents,其他mask掉
- 这样难道不会有太多的agents么?会不会影响速度
- 利用神经网络去决定当前的句子是pos or neg,并且计算confidence score
- Re-labeling with Confidence Consensus
- 有点像模型投票
- $c = c_{sum}/3$,为什么是3呢,因为前文是1 r+2 e
- confidence小于0.5就标记为neg,此时的C对应的是neg的confidence,所以是1-|c|
- Rewards
- global reward $g$ expressing correlations among sub-tasks
- 这里的g是套用的[[TransE]]中的triple score:$$g = ||t_1 + t_r - t_2||$$
- local reward 利用validation上的性能
- hyper-parameter :$\alpha$,控制agents作用大小
- status
训练
$$l^{'}=C^{lamda}l$$
- Loss Correction
- 其中 C是confidence,lamda是scaling factor,当C比较小的时候,对应的新的loss就比较小,也就是影响比较小?
- Training Algorithm


- pre-train
- entity和relation抽取器
- policy network
实验
实验设置
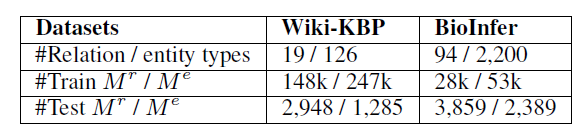
- 数据集
- [[Wiki-KBP]]
- [[BioInfer]]
- [[Baseline]]
- 主要 [[Pipe-lined Methods]]和 [[Joint Methods]]两种,主要针对[[Ren et al_2017_CoType|CoType]]和[[Zeng et al_2015_Distant Supervision for Relation Extraction via Piecewise Convolutional Neural|PCNN]]两种模型
- [[Zeng et al_2015_Distant Supervision for Relation Extraction via Piecewise Convolutional Neural|PCNN]]是pipe-line方法,作为关系抽取模型,set the number of kernel to be 230 and the window size to be 3
- CoType使用原文的参数,并且adopt the same sentence dimension, type dimension and hyper-parameters settings as reported in (Ren et al., 2017)
- KG embeddings,set the dimension to be 50 and pre-train them by TransE
- 我们将[[Stochasitc Gradient Descent | SGD]]和学习率调度程序与余弦退火配合使用以优化agents和提取器,将学习率范围和批处理大小分别设置为[1e-4、1e-2]和64
Multiagents的性能
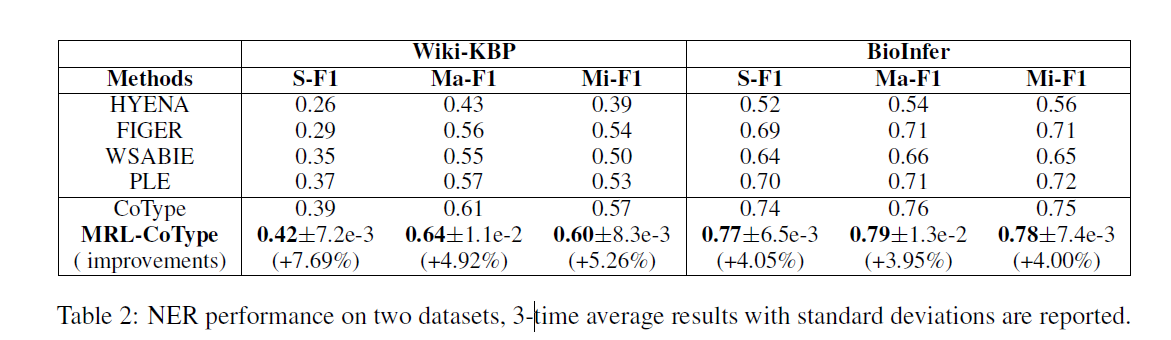
- Entity,使用[[Macro-F1, Micro-F1 and Strict-F1 metrics]]
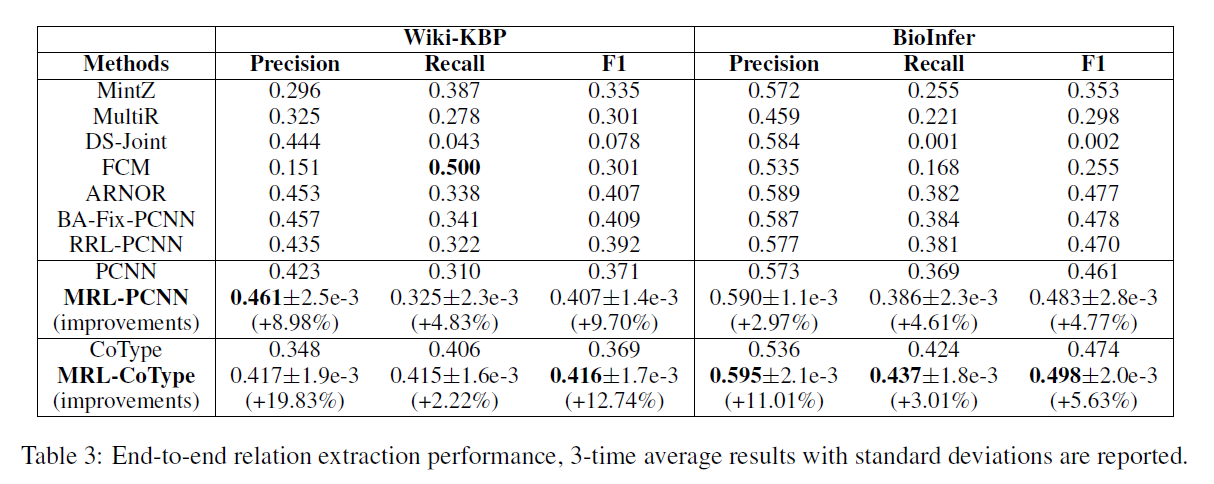
- relation,RRL-PCNN模型P是没有R好的,主要是由于噪音数据在实体抽取时产生的错误级联,本文的模型相比BA-Fix-PCNN可以在不知道test数据的情况下减少偏移标签分布
切片实验

- training settings:
- curriculum learning(课程学习)
- joint multiagents training without CL
- pipe-line
- 对于类型比较多的数据集来说,curriculum的作用更明显
- 更高的平均reward,代表着更高的训练效率,说明决策更加有价值,反馈更加积极
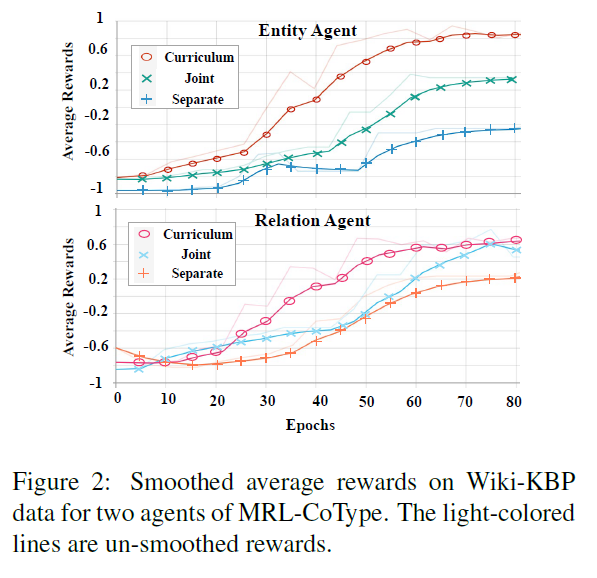
- 因为可以收敛到局部最优从而实现加速,curriculum learning用更少的epochs取得了更好的性能
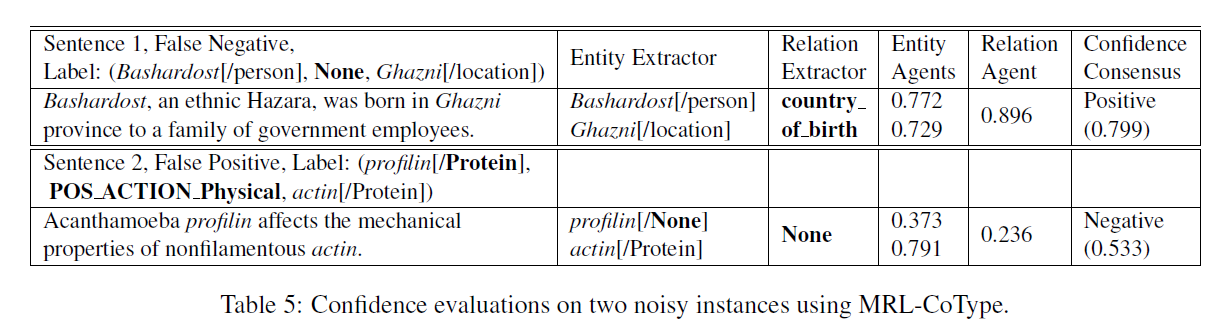
- re-labeling processes