Summary#
- 来源: https://www.aclweb.org/anthology/D19-1021, EMNLP | IJCNLP
- 机构: 清华大学
- 描述论文作者旨在实现或已经实现的研究目标
- 学习带标签数据中的关系相似度度量方式,应用于无标注数据,利用关系知识转移实现开放式关系抽取
- 如果论文中提出了新的方法/技术,那么新方法的关键要素是什么
- 关系孪生网络
- 从带标签的数据中学习到关系知识
- 关系知识转移的方法
- [[Metric Learning]]
- 这篇论文中哪些内容对你来说是有用的
- 不同的损失函数
- 度量学习应用于开放式关系抽取
- 不同的聚类方法
- 你还想要继续阅读哪些参考内容
- [[Metric Learning]]
- 更适合开放式关系抽取的聚类方法,例如本文使用的Louvain
- 损失函数设计
- 问题:大部分开放式关系抽取使用无监督范式,没有利用知识库和标注数据中的关系事实
- 提出:利用关系孪生网络学习有监督数据中的关系相似性度量方式,从而迁移关系知识,识别无监督数据中的新关系
- 实验:significant improvements as compared with other state-of-the-art methods
intro#
- 关系抽取
- 有监督学习效率高,但是数据构建消耗时间和精力
- 半监督方法:bootstrapping,主动学习,label propagation
- 远程监督方法:假设性强,知识库约束
- 很难覆盖开放文本中的相当多样化的新关系
- 开放式关系抽取
- 目的:从开放域文本中抽取出未预先定义过的关系事实
- Banko 2018年直接从句子中抽取短语作为新的关系类型,但是一般不能精确表达关系,包含相同关系的关系短语很难对齐
- Yao 2011年使用聚类做开放式关系抽取,但是大部分都是无监督,不能有效选择有意义的关系类型
- 本文方法:
- 利用高质量的关系抽取的有监督数据,学习关系相似性度量方式,
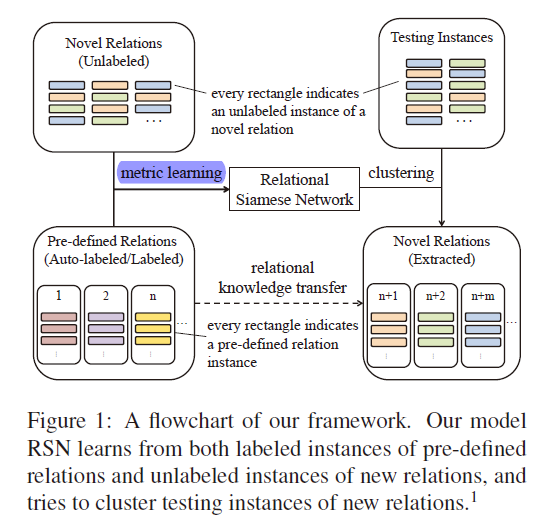
- RSN与有监督、半监督、远程监督方法相结合
- 数据集:FewRel、FewRel-distant,分割成seen和unseen两部分
- “RSN是第一次在聚类开放式关系抽取任务中提出知识迁移的概念”–“To the best of our knowledge, RSN is the first model to consider knowledge transfer in clustering-based OpenRE task.”
- 传统关系抽取其实是分类任务,讲句子中的关系事实分类到预先定义好的关系类型
- Zeng 2014利用CNN编码器,位置嵌入,句子表示
- Lin 2016利用instance-level attention提高了远程监督数据上的性能
- 无法解决一直涌现的开放关系->开放式关系抽取
- 开放式关系抽取
- tagging-based
- 序列标注问题
- 从句子中抽取关系短语->关系短语太具体,下游任务不易于使用
- 无监督(banko)和有监督(jia 2018,cui 2018,stanovsky 2018)
- clustering-based
- 利用外部nlp工具抽取句子特征,然后进行聚类(lin 2001,yao,2011,2012)
- Marcheggiani (2016),无监督数据,离散变分自动编码器
- few-shot learning
- 只有很少的标记样本,关系分类
- (Koch et al., 2015)使用卷积孪生神经网络做图片度量学习,从这里获得启发
- 半监督聚类
- 给目标类别的实例种子,Bair, 2013;Hongtao Lin, 2019
- 该方法中的半监督RSN不适用种子,只使用有监督数据
- 关系相似度计算
- 学习预测两个句子是否包含相同的关系
- CNN利用word和pos embedding输出关系向量v
- 计算绝对距离并映射到
[0,1]
- 交叉熵损失,RSN输出值p作为两个句子包含相同关系的概率值
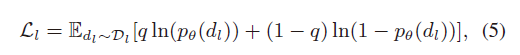
- 半监督RSN
- 模型看到更多种类的数据对于性能是有益处的,所以半监督和远程监督是有必要的
- 聚类假设,远离高密度区域(Chapelle and Zien, 2005)
- 损失函数
- 条件熵损失,远离决策边界,也就是相似概率等于0.5
- 虚拟对抗损失,搜索数据域,惩罚距离预测变化最大的
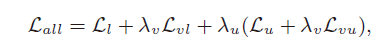
- 远程监督RSN
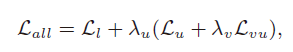
- 去除了VAL,因为会放大远程监督中的错误标签
- 不使用其他降噪方法
- 噪音对于反例来说影响很小
- 在关系密度高的区域进行聚类
- 关系聚类
- HAC(hierarchical agglomerative clustering)
- Louvain
- 基于图的聚类算法
- 不需要预先知道聚类数目
- 二分近似,通过优化社区模块性来寻找合适的聚类数目
- 数据集
- FewRel (Han et al., 2018)
- 每个句子都包含一个独有的实体对,防止记忆实体和关系
- 64+16关系,1600测试集
- FewRel-distant
NYT-FB (Marcheggiani and Titov, 2016)
- 实验结果分析
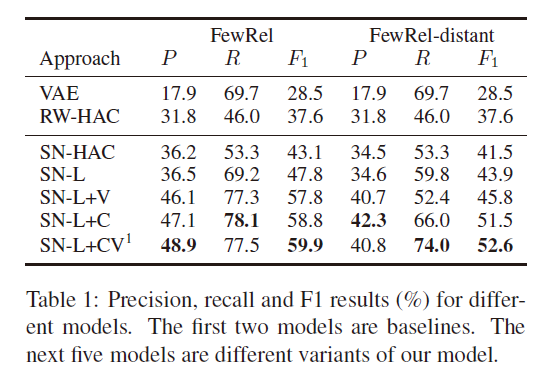
- RW-HAC,SN-HAC,孪生网络更能捕捉句子关系信息,分布式特征表示,优化信息聚合
- Louvain性能优于HAC,没有使用额外的约束,关系聚类可能有奇怪的形状,违背了HAC的假设
- VAT可能放大了噪音数据